Design Overview
System Context
The Fusion Data Platform (FDP) brings together tools for collecting, curating, analyzing, and publishing fusion data. It helps users process raw data from experiments, build reusable workflows, and share results through a shared, federated system. FDP interacts with a variety of users and systems, each playing a different role in how data flows through the platform.
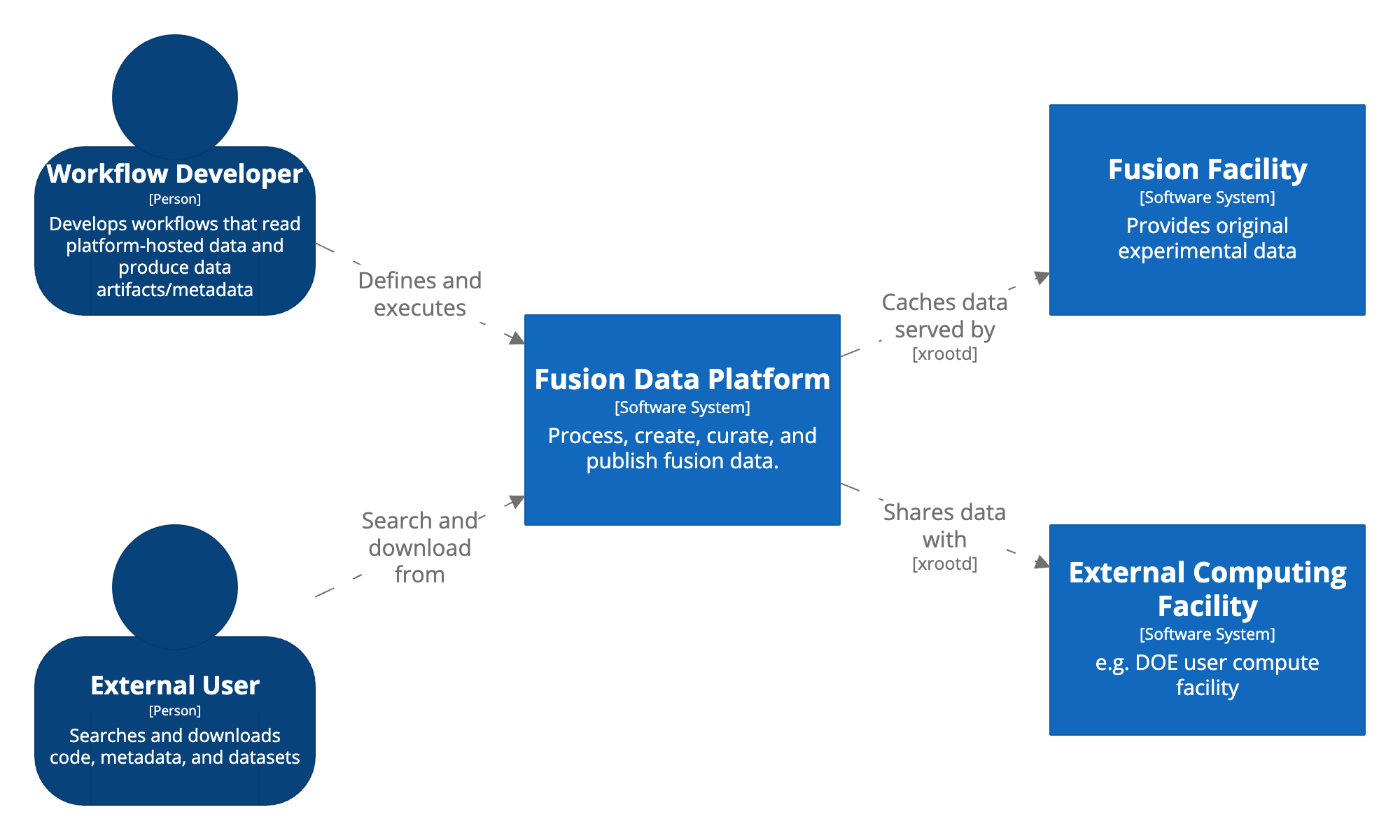
Platform Users
Workflow Developers use the platform to build data processing pipelines. These workflows might include scripts, ML models, or analysis steps written using APIs like TokSearch. The workflows run on cached experimental data and produce outputs that can be tracked and shared.
External Users typically access FDP through the MetaHub web portal. They use it to search for datasets, workflows, and metadata. This group includes scientists, analysts, or tool developers who want to work with curated results but don’t need to build workflows from scratch.
External Systems
FDP connects to two main kinds of external systems:
-
Fusion Facilities, like DIII-D, supply experimental data through their local storage systems. That data is shared using the Open Science Data Federation (OSDF) and the Pelican platform, which is built on the XRootD stack.
-
External Computing Facilities, like DOE user computing centers, run large-scale analyses using data and workflows published by FDP. These facilities access the data through OSDF caches.
These connections form the boundary between FDP and the broader research ecosystem, and set the stage for the architecture described in the following sections.
The architecture of FDP is explained using a set of C4 diagrams that show how all the parts fit together—from user-facing tools to facility integrations and workflow components.