User-defined Workflows
What's Inside a Workflow
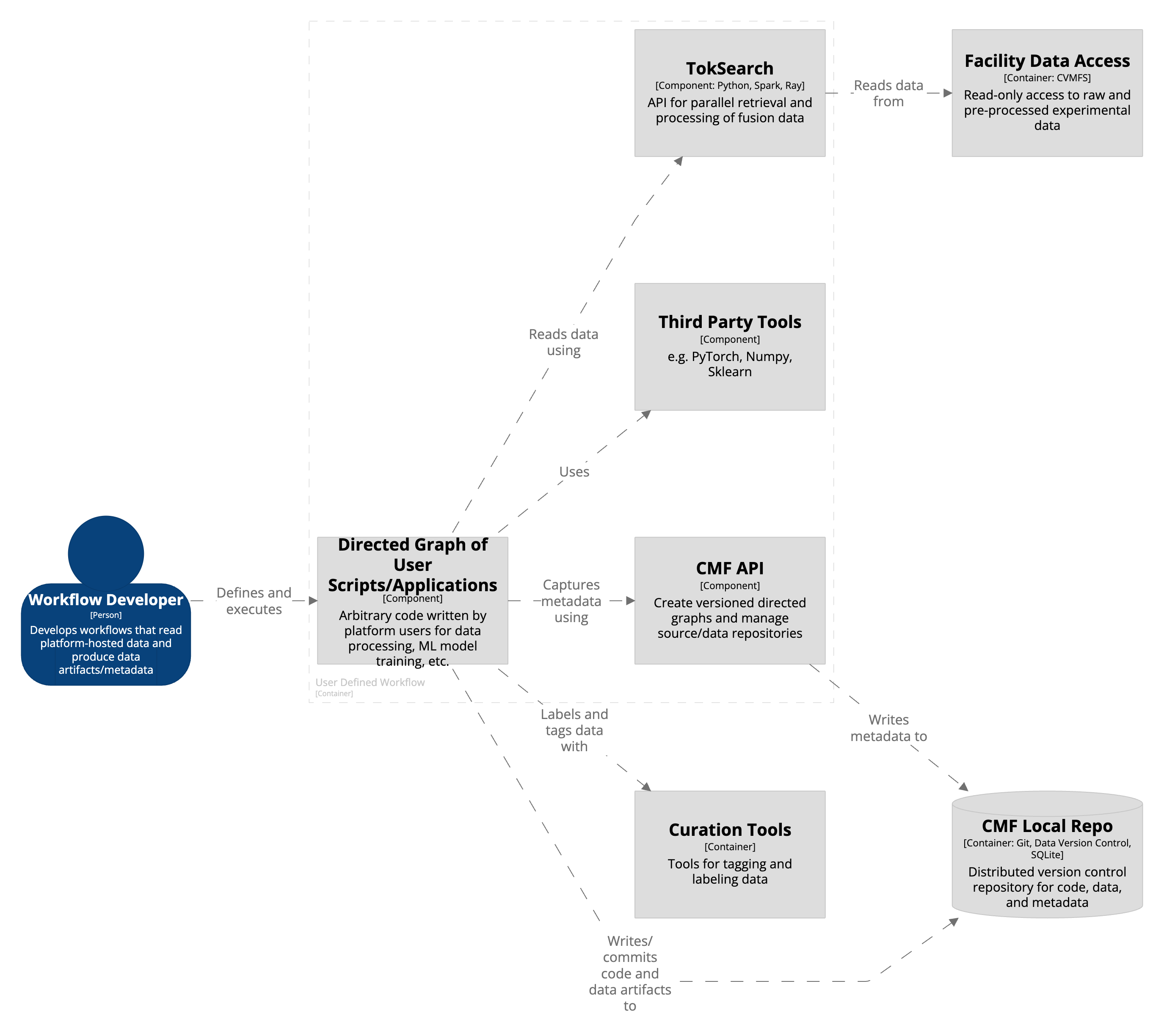
FDP workflows are built from modular components that process cached experimental data, extract features, train models, and record results. This section breaks down how those components fit together.
The Workflow as a Graph
Each workflow is a directed acyclic graph (DAG). It’s made up of custom scripts or tools that do things like clean data, align signals, compute features, train ML models, or add metadata. The DAG structure makes sure each step runs in the right order and allows for parallel execution when possible.
Key Components
TokSearch is the data access engine. It pulls fusion data at scale, using either node-local multiprocessing or distributed backends like Ray and Spark. Pipelines are written in Python and can run on anything from a laptop to a cluster.
Third-Party Tools like NumPy, SciPy, PyTorch, and scikit-learn are used in many workflows. Because TokSearch uses standard Python data types, it's easy to plug in these libraries for things like signal processing or model training.
CMF API helps with versioning and metadata. It records what the workflow did, what data it used, and what it produced—all as a graph of linked steps and artifacts that can be saved to the repository.
Outputs and Versioning
Workflows save their results—whether datasets, model outputs, or visualizations—into the local CMF repository. These outputs can be pushed to the public repository so they show up in MetaHub.
How It Runs
A user defines the workflow as a set of steps. Each one reads from the facility cache, processes the data, writes outputs to the CMF repo, and adds metadata. Once complete, everything is versioned and shareable.