Data Federations
How FDP Connects to Facility Data
FDP makes it possible to access fusion data from multiple facilities through a unified interface. This is done using a federated system built on the Pelican platform, which supports scalable, secure data sharing through a network of cache servers.
Where the Data Comes From
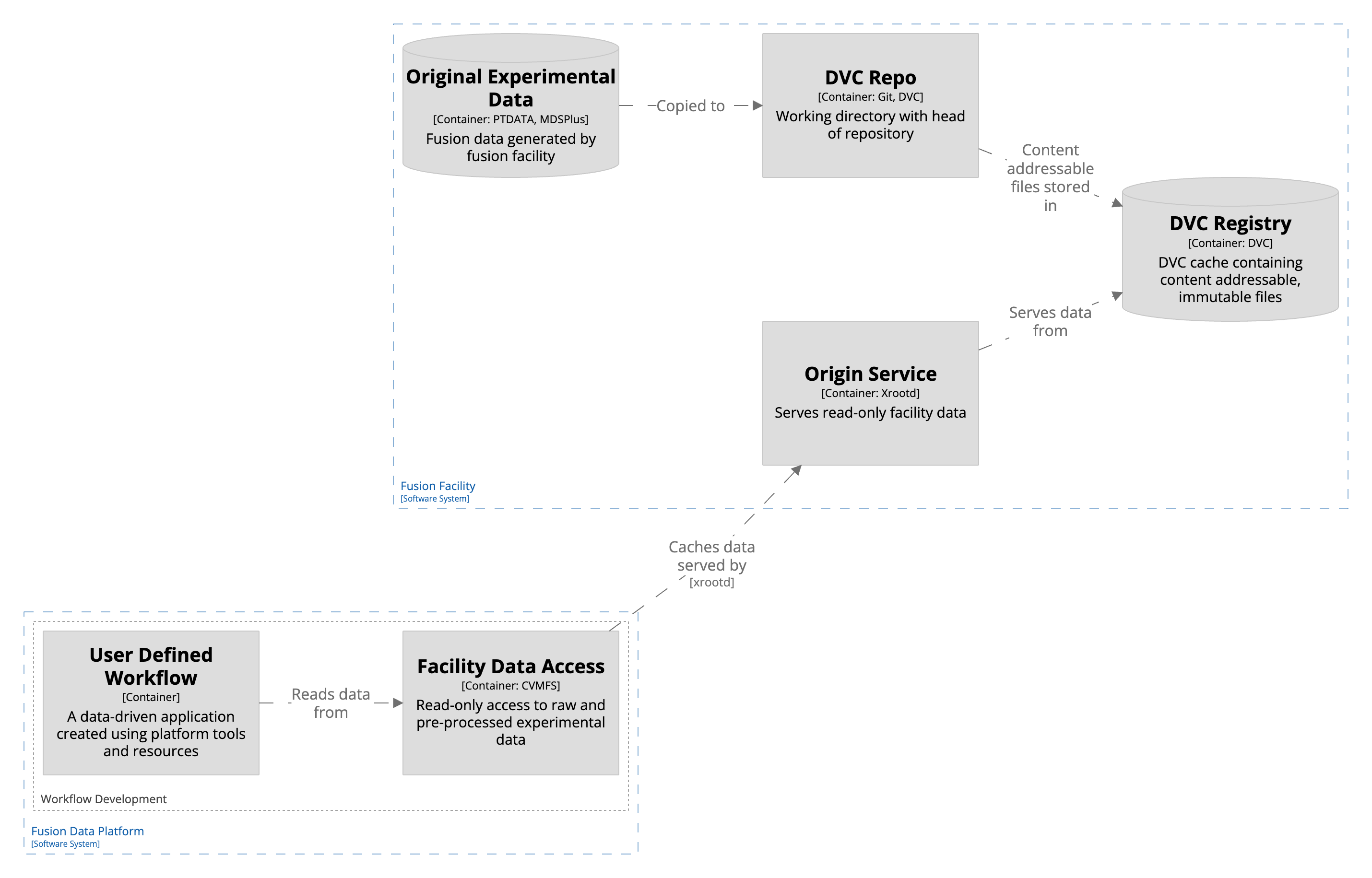
Each fusion facility runs an origin service, which acts as the official source for its experimental data. These services expose data directly from the facility’s storage systems—including legacy formats like MDSplus and PTDATA—without needing to copy the files somewhere else.
To keep existing tools working smoothly, FDP makes this data available through the XRootD POSIX interface. That means older software can access data using standard file operations, while still benefiting from the performance and transparency of Pelican’s caching system.
How Caching Works
Pelican uses a tiered caching system. Data is copied from origin servers to caches that are closer to where users and compute resources are located. These caches use content-based identifiers so that the right data can be fetched reliably and efficiently.
At analysis sites (like supercomputers), a local cache automatically retrieves requested data from facility origins. Tools like TokSearch pull data through this mechanism so users don’t need to manually download files or manage data transfers.
Keeping Access Secure
Access to FDP’s federated data is protected by token-based authentication using SciTokens. This makes sure only authorized users can access private datasets and that access is logged and traceable. Tokens can be passed along with workflows or through command-line tools so users don’t have to manage login steps for every action.